

1108 words
6 minutes
langchain入门
chatbot
一个简单的chatbot由
- 生成提示词文本的模板
from langchain.prompts import ChatPromptTemplate promot_template = ChatPromptTemplate.from_messages( [ ('system', '你是一个诗人,帮我根据用户的输入写一首现代诗'), ('human', '{ipt}') ] ) - 预训练模型
from langchain_openai import ChatOpenAI apikey = "********" model = ChatOpenAI( model="moonshot-v1-8k", max_tokens=1024, api_key=apikey, temperature=0.7, base_url="https://api.moonshot.cn/v1", ) - 解析模型输出
def out_parser(opt): return '##'+opt.__str__()
三部分组成。其中在第三部分,甚至可用套用其他大模型进行解析。 三个模块之间的联系使用|完成。有点管道的味道在了。
chain = promot_template | model | out_parser
ans = chain.invoke(input={'ipt':'夕阳,车流'})
Agent
智能体。下述将描述利用def函数中docs以及duckduckgo搜索引擎来实现RAG。
- 定义model
from langchain_openai import ChatOpenAI apikey = "********" model = ChatOpenAI( model="moonshot-v1-8k", max_tokens=1024, api_key=apikey, temperature=0.7, base_url="https://api.moonshot.cn/v1", ) - 导入内置duckduckgo工具和自定义工具装饰器tool,并绑定模型
查看工具调用情况:from langchain_community.tools import DuckDuckGoSearchRun from langchain.tools import tool tools = [findCapital, DuckDuckGoSearchRun()] model_with_tools = model.bind_tools(tools) @tool def findCapital(cname): '''根据国家名查找首都名 cname为str数据类型,传入cname,获得返回的国家首都信息 ''' cname = cname.strip() df = pd.DataFrame({ '国家': ['中国', '美国', '日本'], '首都': ['北京', '东京', '华盛顿'], }) return df[df["国家"]==cname]["首都"].values[0].__str__()
输出结果:根据函数docs选择了该函数from pprint import pprint as pp resp = model_with_tools.invoke("中国的首都是哪里, ") pp(dict(resp))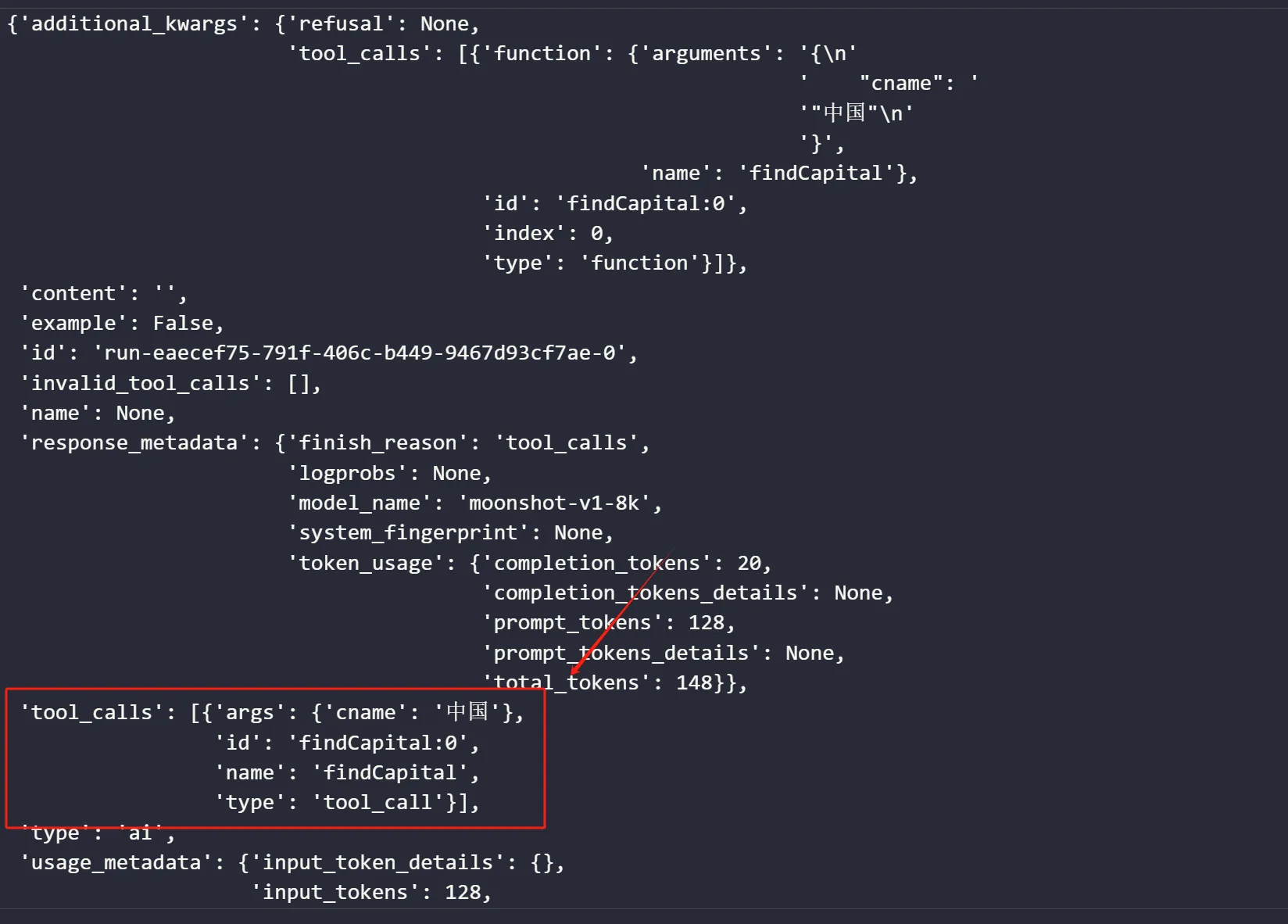
- 将模型与检索后的信息联系起来,构建Agent
使用Agentdef Agent(q:str, model:ChatOpenAI, tools:list[tool]): model_with_tools = model.bind_tools(tools) model_opt = model_with_tools.invoke(q) ##返回值记录着需要用到的工具名 tool_resp = call_tool(model_opt, tools) final_resp = model.invoke( f'original query:{q}\n\n\n tool response:{tool_resp}', ) return final_resp def call_tool(model_opt, tools): tools_map = {tool.name.lower():tool for tool in tools} print(tools_map) tools_resp = {} for tool in model_opt.tool_calls: tool_name = tool['name'].lower() tool_args = tool['args'] tool_instance = tools_map[tool_name] tool_resp = tool_instance.invoke(*tool_args.values()) tools_resp[tool_name] = tool_resp print(tool_name, ' ', tool_resp) return tools_respres = Agent("今天深圳天气如何", model, tools) print(res.content)
pdf语义搜索
文档和文档加载器 一个pdf加载成一系列
Document对象,一个对象通常是一页,包含- page_content:页面内容
- metadata:文件名和文件页码
分割 进一步拆分我们的 PDF 将有助于确保文档相关部分的含义不会被周围文本“冲淡”。 主要参数:
- 块大小:chunk_size
- 重叠字数:chunk_overlap
矢量存储Embedding 将文本转为数值向量。依托于文本向量化模型。
矢量存储VectorStore Embedding模型为文本向量化模型。VectorStore将文本向量化模型作为一个参数,对文档等知识建立索引与存储。
- 根据字符串相似度返回文档
- 异步查询
- 返回分数并根据字符串相似度返回文档
- 将文本先进行embedding,再根据向量到VectorStore中进行数据查询
检索器Retrievers VectorStore未实现类似Runnable的方法。检索器是一个Runable对象。可以通过一个VectorStore实例构建一个Retriever对象。
retriever = vector_store.as_retriever(
search_type="similarity",##调用底层向量存储的方法名字
search_kwargs={"k": 1},##参数化
)
retriever.batch(
[
"How many distribution centers does Nike have in the US?",
"When was Nike incorporated?",
],
)
具有结构化输出的LLM:评价/打分
使用pydantic库实现构建一个具有结构化输出的LLM。可以实现类似评分和分类的功能。
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
class Classification(BaseModel):
sentiment: str = Field(description="The sentiment of the text")
aggressiveness: int = Field(
description="How aggressive the text is on a scale from 1 to 10"
)
language: str = Field(description="The language the text is written in")
# LLM
llm = ChatOpenAI(temperature=0, model="gpt-4o-mini").with_structured_output(
Classification
)
更精细的控制,使用枚举来控制之前提到的每个方面。
class Classification(BaseModel):
sentiment: str = Field(..., enum=["happy", "neutral", "sad"])
aggressiveness: int = Field(
...,
description="describes how aggressive the statement is, the higher the number the more aggressive",
enum=[1, 2, 3, 4, 5],
)
language: str = Field(
..., enum=["spanish", "english", "french", "german", "italian"]
)
从非结构化数据中提取结构化数据
- schema 描述我们需要从文本中提取哪些消息
from typing import Optional
from pydantic import BaseModel, Field
class Person(BaseModel):
"""Information about a person."""
# ^ Doc-string for the entity Person.
# This doc-string is sent to the LLM as the description of the schema Person,
# and it can help to improve extraction results.
# Note that:
# 1. Each field is an `optional` -- this allows the model to decline to extract it!
# 2. Each field has a `description` -- this description is used by the LLM.
# Having a good description can help improve extraction results.
name: Optional[str] = Field(default=None, description="The name of the person")
hair_color: Optional[str] = Field(
default=None, description="The color of the person's hair if known"
)
height_in_meters: Optional[str] = Field(
default=None, description="Height measured in meters"
)
Optional[str] 字段告诉模型所给文本中没用相关信息时,可以不回答。
- 提取器
from langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-4o-mini", model_provider="openai")
structured_llm = llm.with_structured_output(schema=Person)